Semantic Scene Completion from a Single Depth Image
Abstract
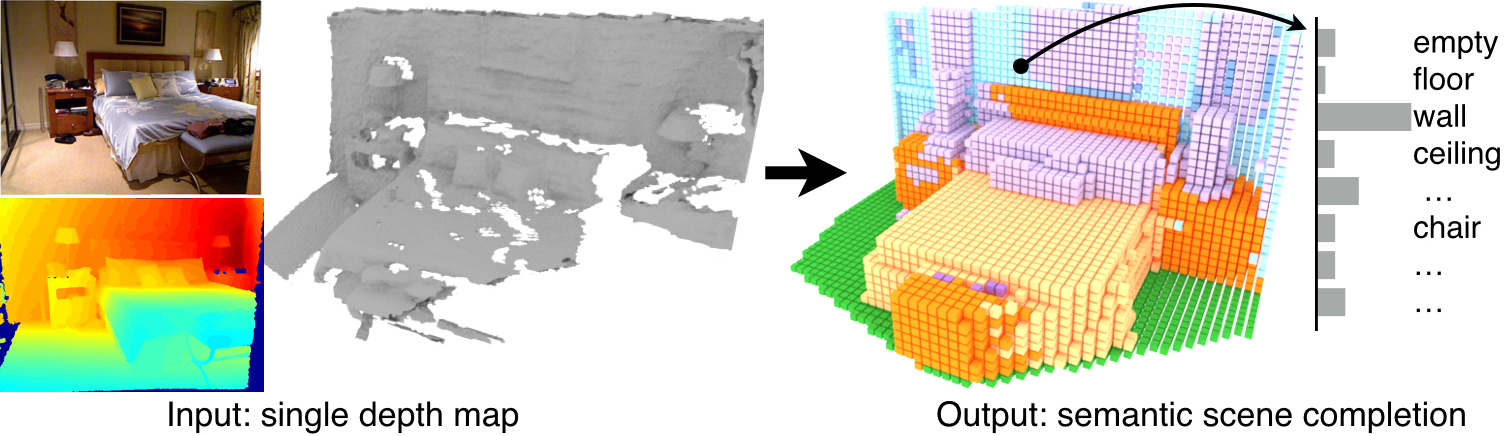
This paper focuses on semantic scene completion, a task for producing a complete 3D voxel representation of volumetric occupancy and semantic labels for a scene from a single-view depth map observation. Previous work has considered scene completion and semantic labeling of depth maps separately. However, we observe that these two problems are tightly intertwined. To leverage the coupled nature of these two tasks, we introduce the semantic scene completion network (SSCNet), an end-to-end 3D convolutional network that takes a single depth image as input and simultaneously outputs occupancy and semantic labels for all voxels in the camera view frustum. Our network uses a dilation-based 3D context module to efficiently expand the receptive field and enable 3D context learning. To train our network, we construct SUNCG - a manually created large-scale dataset of synthetic 3D scenes with dense volumetric annotations. Our experiments demonstrate that the joint model outperforms methods addressing each task in isolation and outperforms alternative approaches on the semantic scene completion task.
Paper
-
Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser
Semantic Scene Completion from a Single Depth Image ( CVPR 2017 )
[paper] [bibtex] [code] [poster] [talk] [slides]
SUNCG Dataset
- If you are a researcher and would like to get access to the data, please print and sign this [agreement] and email it to suncgteam@googlegroups.com.
- To explore the dataset, you can visit the [SUNCG dataset webpage] .
- We provide a simple C++ based toolbox for the SUNCG dataset. You can obtain the toolbox from this [GitHub repository] .
